Le elaborazioni sequenziali
Il 7070 era un calcolatore dotato di soli nastri e quindi le uniche elaborazioni possibili con quel tipo di macchina erano le elaborazioni sequenziali.
E' inutile dire che tutte le elaborazioni erano di tipo batch e tutti gli aggiornamenti degli archivi venivano effettuati periodicamente.
Ad esempio il principale programma della procedura dei Conti Correnti, che veniva eseguito ogni giorno, aveva il compito di aggiornare l'archivio su nastro contenente la situazione di ciascun conto e per far ciò si avvaleva di un altro nastro su cui erano stati registrati tutti i movimenti della giornata.
Poichè l'inventario dei conti tenuto su nastro non poteva consentire un aggiornamento diretto, occorreva leggere l'intero inventario da un'unità a nastro e i movimenti da un'altra unità e scrivere in output un nuovo nastro inventario in cui i records non movimentati erano ricopiati senza mdifiche, mentre quelli movimentati erano scritti dopo gli opportuni aggiornamenti; per fare questo era necessario però che sia l'inventario sia i movimenti fossero ordinati opportunamente (nel nostro caso per codice filiale, categoria di conto e numero di conto).
Quanto detto dimostra chiaramente la necessità di disporre di un importante programma capace di ordinare i records di un file presente su nastro magnetico; il programma naturalmente esisteva, si chiamava SORT/MERGE ed era fornito dalla IBM.
Il programma di aggiornamento dei Conti Correnti prevedeva di utilizzare tre unità a nastro su cui erano montati i files di input e due unità di output su cui venivano scritti i risultati, in particolare:
- I tre files di input erano rispettivamente: l'inventario precedente (INV), i movimenti del giorno selezionati, cioè ordinati (MOVS) e il file MGE (Movimenti Giornalieri Errati) della lavorazione precedente (il compito di questo file sarà più chiaro successivamente); tutti e tre questi files erano ovviamente ordinati secondo una "chiave" costituita da codice filiale, categoria e numero di conto; i due files di output erano l'inventario aggiornato e il file MGE di output.
- Il programma leggeva i tre files tenendoli allineati per chiave; se si trovava in presenza di un record inventario per il quale non esistevano dati di agggiornamento provenienti da MOVS o da MGE, riscriveva sul file INV di output, l'INV di input senza modifiche; viceversa scriveva in output un record INV aggiornato con i dati provenienti da MOVS e/o MGE.
- Durante l'aggiornamento si potevano verificare vari casi di errore, ad esempio un movimento si poteva riferire ad un conto inesistente, oppure un movimento di prelievo poteva non trovare capienza nel saldo, ecc.; in tutti questi casi il movimento che per qualche motivo non poteva agire veniva scritto sul file MGE di output che successivamente veniva trattato da un altro programma che provvedeva a stampare il tabulato delle anomalie.
- Gli uffici controllo esaminavano quei tabulati e provvedevano a fare le correzioni necessarie (potevano inserire un record di saldo mancante o modificare un saldo o cancellare un movimento e inserirne uno con numero di conto diverso, ecc.); queste correzioni venivano apportate a penna sui tabulati, poi quest'ultimi venivano mandati nel reparto perforazione dove gli operatori addetti le riportavano su schede appositamente codificate; queste schede, venivano poi portate su nastro insieme alle schede dei movimenti della giornata successiva e il nastro risultante (MOV) veniva ordinato per la solita chiave, ottenendo finalmente il nuovo MOVS.
Credo che ora si può capire come ad ogni elaborazione il nastro inventario corrente diventasse sempre più aggiornato; infatti ad ogni lavorazione agivano una gran parte dei movimenti del giorno e una gran parte delle correzioni relative ai giorni precedenti.
Al momento di produrre gli estratti conto e/o le liquidazioni, poichè si desiderava avere un inventario senza errori, si eseguivano varie lavorazioni di aggiornamento fino ad ottenere un MGE completamente vuoto, cioè una situazione in cui tutti gli errori erano stati corretti.
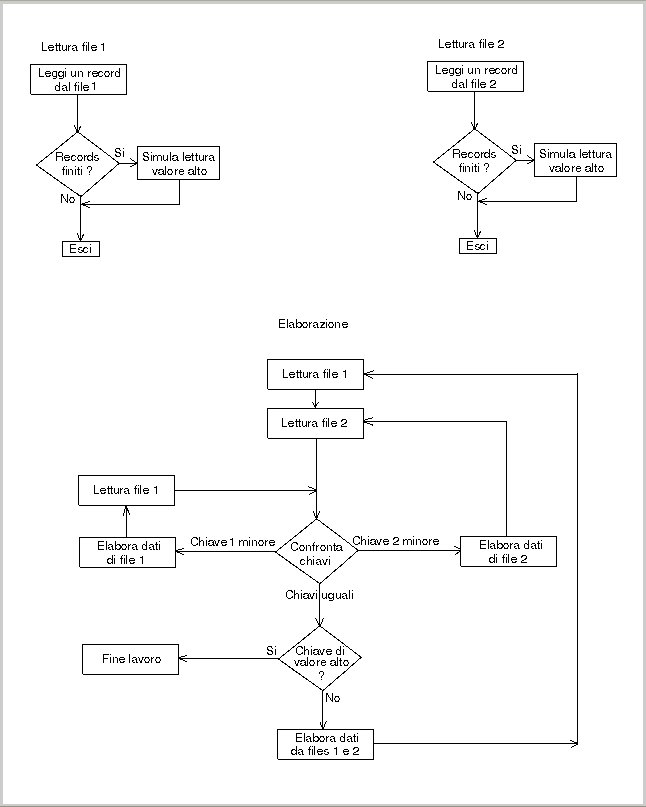
Ho descrrito questo tipo di elaborazione, che poi si ripeteva abbastanza similmente anche per le altre procedure, perchè è mia intenzione sottolineare come uno dei problemi dei primi programmatori (che avevano a che fare soltanto con elaborazioni sequenziali) fosse quello di leggere più files tenendoli allineati per chiave; l'accoppiamento di due files risultava abbastanza semplice, ma accoppiarne tre o più di tre diventava molto più difficile; qui di seguito ho riportato un diagramma a blocchi che mostra come si usava leggere ed accoppiare due files.